Open Science
What happens to the data that we collect?
Publically funded research studies, including SCALES, are often required to make their anonymised research data openly available for other people to access. Some journals require that data are deposited when papers are published. This allows other researchers to repeat our analyses and learn from the information we have provided. We can also store our data in general data repositories, like the UK Data Archive or Wellcome Open Research, which allow other researchers to download datasets. This improves the value for money of research studies, because other researchers can answer new research questions using existing data, rather than having to get more money to assess more children on similar measures. For instance, in SCALES we are very interested in how language changes over time. Another research team might be specifically interested in how early attention skills change over time. Because we measured attention as well as language at every time point, these researchers could use our data to answer this question, saving lots of time and money.
We have also collected a large number of language samples (stories the children tell in relation to picture prompts). We generally measure the amount of information children convey in these stories, but other researchers, like linguists, could look in more detail at the words and sentence structures children use. By collecting these stories at multiple time points, it is easier to see how these skills develop over time. Such information could help with the identification of new tools for deciding when children need extra help with language.
Any data that we deposit is anonymised. This means that we carefully go through the database to remove any information that could enable individual children, families or schools to be identified. This would include removal of names, addresses/phone numbers/emails, dates of birth, school names, voice or video recordings, any specific information about diagnosis. The picture below is an example of what a section of our anonymised data looks like:
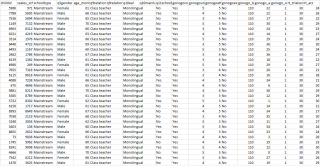
We will therefore be depositing SCALES data from reception through to Year 8 on approved repositories (such as the UK Data Archive). Narrative samples will be donated to the CHILDES database of children’s language.
Once data are deposited we no longer have control over where the data go or what questions are asked of the data. It will therefore not be possible to withdraw individual data from the study after it is deposited. However, no new research teams will be able to contact you directly in connection with SCALES, as they will not be able to access any personal details or contact information. Also note that we do not ever sell data or information to other companies and we do not make any money from sharing our data. It is purely to further scientific goals and to ensure maximum value from this incredible resource to which you have so generously contributed.